Convertir efficacement document Word en document HTML avec une macro VBA Word
SOMMAIRE
I Introduction
III écritures de la méthode de conversion des styles Word en balises HTML
III Extraction des images
IV Conclusion
I introduction
Dans ce tutoriel, je vais vous montrer comment convertir un fichier Word au format HTML de façon précise sans les balises HTML générées par Word automatiquement. Pour ce faire nous utiliserons une macro VBA qui nous permettra de lire le texte séquentiellement afin de trouver tous les styles et de les convertir en balises HTML correspondantes. Nous écrirons aussi une méthode qui nous permettra de d'extraire toutes les images issues d'un document Word et de les sauvegarder dans un répertoire particulier.
II Ecriture de la méthode de conversion des styles Word en balises HTML
Dans cette partie nous allons voir comment parcourir séquentiellement le texte d'un document pour y trouver tous les différents styles de texte afin de les convertir en balises HTML correspondantes. Mais avant de commencer il va falloir dans un premier temps créer notre nouvelle macro. Pour ce faire il faut vérifier que vous avez accès aux outils de développement permettant de créer cette macro dans Word. Afin de le vérifier il faut ouvrir l'application Word et vérifier que vous avez l'onglet développement sur le ruban. Ou alors que dans la barre d’outils d’accès rapide, vous avez accès à la commande nommée "code". Si ce n'est pas le cas vous pouvez le faire en ouvrant les options par l'intermédiaire de l'onglet fichier. Puis ensuite en sélectionnant la commande « barre d'accès rapide » et en sélectionnant la commande "Code", comme ceci :
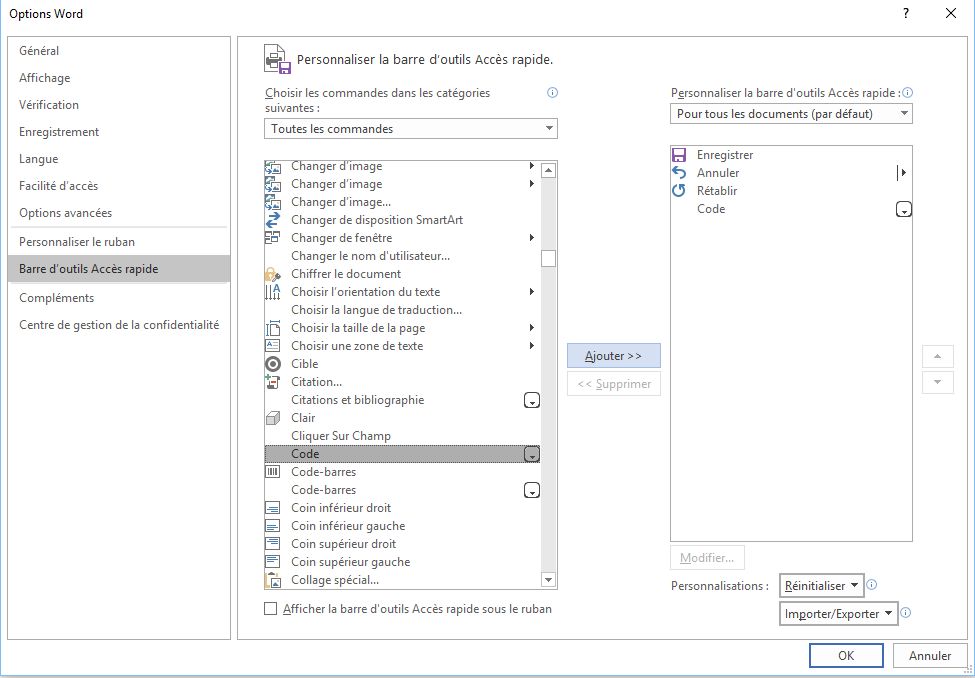
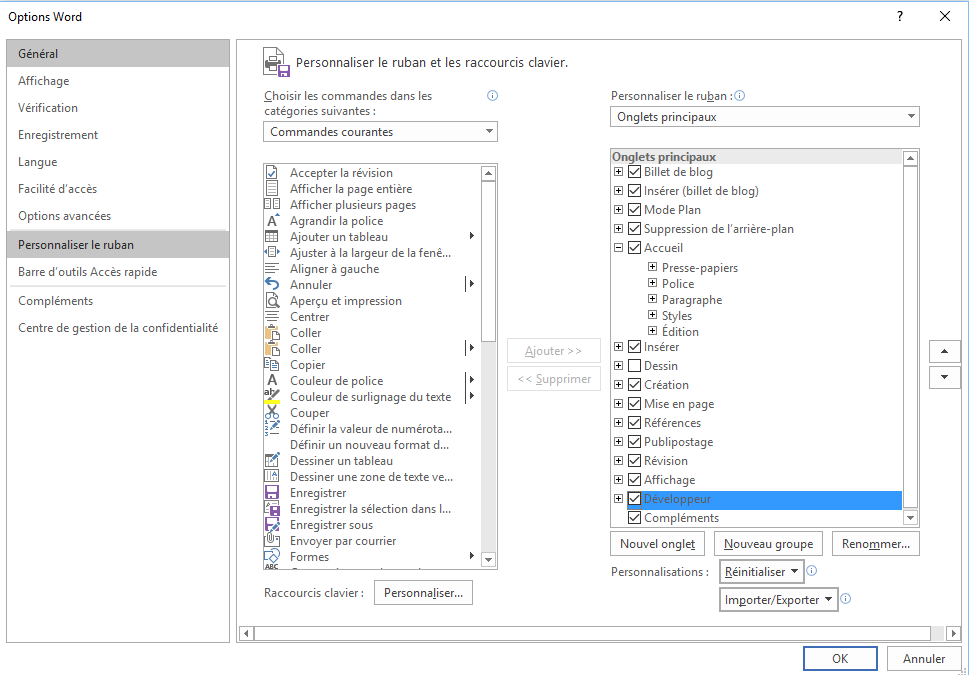
Une seconde option vous permet de rajouter l’onglet Développeur dans le Ruban. Pour ce faire il suffit d’ouvrir les options de Word et de sélectionner la commande "Personnaliser le Ruban" et de cocher l'onglet « Développeur » dans la liste des onglets principaux disponibles.
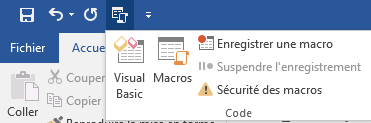
Ensuite pour créer une nouvelle macro Word qui sera utilisée pour tous les documents que nous écrirons dans le futur, il suffit d'appuyer sur le bouton "Macros" en sélectionnant l’icône de « Code » dans la barre d’accès rapide ou directement dans l’onglet « Développeur » :
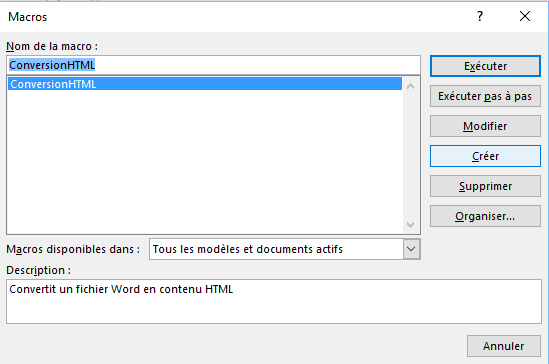
Puis ensuite appuyer sur le bouton "créer" après avoir nommé votre nouvelle macro.
Nous allons maintenant passer à l’écriture de notre macro. Commençons d’abord par créer la méthode qui va permettre de d’analyser différents styles de notre document et qui sera nommée ‘ConversionHTML’. Nous allons d’abord définir quelques variables qui seront utiles dans notre méthode. Voici les différentes variables utilisées :
Dim strMyFile As String
Dim strMyProfilePath As String
Dim strtextTemp, strtextToCopy As String
Dim oPara As Paragraph
Dim Line As Byte
La chaîne de caractères « strMyFIle » permettra de stocker le chemin de notre fichier à convertir. La chaîne de caractères « strMyProfilePath » permettra de stocker le chemin complet pour accéder au dossier documents de l’utilisateur actif. Les variables « strtextTemp » et « strtextToCopy » permettra de gérer le texte de chaque paragraphe nous allons itérer dans cette méthode. La variable « oPara » permet d’accéder à chaque paragraphe de notre document. La variable Line quant à elle va nous permettre gérer le nombre de lignes incluses dans une liste de puces. Voilà maintenant pouvons entrer dans le vif du sujet. Commençons d’abord par initialiser les variables qui vont nous permettre de définir le chemin d’accès à notre profil ainsi que le nom du fichier converti. Voici le code correspondant :
strMyProfilePath = Environ("USERPROFILE") & "\Documents" & "\Temp\"
strMyFile = strMyProfilePath & Split(ActiveDocument.Name, ".")(0) & ".html"
Comme vous pouvez le constater VBA utilise les variables d’environnement avec la méthode Environ à laquelle nous donnons comme paramètre la variable d’environnement correspondante. Cette variable d’environnement donne juste l’accès au répertoire utilisateur. Dans notre cas nous voulons ranger le fichier dans le dossier documents de l’utilisateur dans un sous-dossier se nommant « temp ». Pour donner le nom complet de notre fichier HTML converti utilise la variable précédemment initialisée et nous et lui ajoutons le nom du fichier Word correspondant sans l’extension puis nous rajoutons l’extension HTML. Maintenant nous pouvons ouvrir ce fichier en lecture écriture afin de pouvoir y mettre le texte converti. Pour ce faire on utilise le code suivant
Open strMyFile For Append As #1
…
Close #1
Dans un deuxième temps il nous faut énumérer chaque paragraphe de notre document. Pour ce faire on va utiliser la boucle suivante :
For Each oPara In ActiveDocument.Paragraphs
…
Next
Donc on va parcourir tous les différents paragraphes de ce document afin de pouvoir convertir le texte correspondant. Ce qui nous donne à peu près le code suivant :
Open strMyFile For Append As #1
For Each oPara In ActiveDocument.Paragraphs
strtextTemp = .Text
…
Next
Close #1
Au sein de cette boucle nous allons itérer les paragraphes par rapport à leur style. Pour récupérer texte correspondant au paragraphe en question nous utilisons la propriété Text appliquée à la propriété Range de l’objet paragraphe correspondant.
Et dans un premier temps nous allons d’abord tester si le paragraphe est une liste à puces. Car c’est le style de document le plus complexe à prendre en compte. En effet avec ce style on considère que chaque ligne est un paragraphe à lui tout seul. De plus on ne HTML les listes à puces sont gérées de la façon début de la liste à puces correspond à la balise <ul> chaque ligne devra commencer par une balise <li> et se terminait par une balise </li>. La liste à puces se termine par la balise </ul>. Nous allons donc utiliser une condition de cette forme :
If .ListFormat.ListType = wdListBullet Then
If Line = 0 Then
strtextToCopy = "<ul>li>" & strtextTemp & "</li>"
Else
strtextToCopy = "<li>" & strtextTemp & "</li>"
End If
Line = Line + 1
Else
If Line <> 0 Then
strtextToCopy = "</ul>"
Line = 0
Else
strtextToCopy = ""
End If
Pour savoir si nous sommes en présence d’une liste à puces, VBA met à notre disposition la propriété « wdListBullet ». Si nous sommes dans ce cas-là, nous itérons chaque ligne afin d’appliquer les balises correspondantes aux listes à puces en html.
Si nous ne sommes pas en présence d’une liste à puces, nous allons pouvoir tester les différents styles appliqués à nos paragraphes. Dans ce tutoriel nous allons tester quelques styles comme par exemple :
- Le titre principal (style « Titre ») ;
- Le titre secondaire (style « Titre 1 ») ;
- le style « Normal » correspond au texte de nos paragraphes ;
- et enfin le style « Image » qui est un style personnalisé permettant d’appliquer les balises correspondantes en HTML.
Voilà la liste n’est pas complète mais vous aurez le loisir de rajouter les styles dont vous avez besoin.
Voici le code correspondant à cette partie :
Select Case oPara.Style
Case "Titre"
strtextToCopy = strtextToCopy & “<h1>" & strtextTemp & “</h1>"
Case "Titre 1"
strtextToCopy = strtextToCopy & "<h2>" & strtextTemp & "</h2>"
Case "Normal"
strtextToCopy = strtextToCopy & "<p>" & strtextTemp & "</p>"
Case "Image"
strtextToCopy = " <div id='image'><img src='images_fichiers/image’" & ImgNbr & "’.png' alt='description image'/></div>"
ImgNbr = ImgNbr + 1
End Select
End If
C’est avec la propriété Style que nous pouvons tester les différents styles que nous venons d’énumérer. Nous avons utilisé une structure de test Select Case pour que le code soit plus compréhensif. Les balises de titres sont converties en html par les balises correspondantes c’est-à-dire <h1> ...</h1> pour le titre principal, <h2>…</h2> pour les titres secondaires Une fois que le document a été parcouru entièrement pouvons le fermer ce qui a pour conséquence de sauvegarde sur le disque.
En ce qui concerne les images le plus simple est de créer un style personnalisé nommé « Image » et de l’appliquer à chaque fois que vous insérez une nouvelle image dans votre document. Lorsque le script rencontre ce type de style, il applique la balise <img/> encadrée par des balises <div></div>. Le nom de chaque fichier image sera généré automatiquement lors de la sauvegarde de notre document au format HTML dans la partie suivante.
Nous en avons fini avec la méthode de conversion des balises, nous allons maintenant voir comment extraire les différentes images d’un document Word.
Voici le code intégral de la méthode :
Sub ConversionHTML()
'
' ConversionHTML Macro
' Convertit un fichier Word en contenu HTML
'
Dim oMyApplication As Object
Dim strMyFile As String
Dim strMyProfilePath As String
Dim strtextTemp, strtextToCopy As String
Dim oPara As Paragraph
Dim Line As Byte
Set oMyApplication = CreateObject("WScript.Shell")
strMyProfilePath = Environ("USERPROFILE") & "\Documents" & "\Temp\"
strMyFile = strMyProfilePath & Split(ActiveDocument.Name, ".")(0) & ".html"
Open strMyFile For Append As #1
Line = 0
ImgNbr = 1
For Each oPara In ActiveDocument.Paragraphs
With oPara.Range
strtextTemp = .Text
If strtextTemp <> " " Then
If .ListFormat.ListType = wdListBullet Then
If Line = 0 Then
strtextToCopy = "<ul><li>" & strtextTemp & "</li>"
Else
strtextToCopy = "<li>" & strtextTemp & "</li>"
End If
Line = Line + 1
Else
If Line <> 0 Then
strtextToCopy = "</ul>"
Line = 0
Else
strtextToCopy = ""
End If
Select Case oPara.Style
Case "Titre"
strtextToCopy = strtextToCopy & "<h1>"& strtextTemp & “</h1>"
Case "Titre 1"
strtextToCopy = strtextToCopy & "<h2>" & strtextTemp & "</h2>"
Case "Normal", "Sans interligne"
strtextToCopy = strtextToCopy & "<p>" & strtextTemp & "</p>"
Case "Image"
strtextToCopy = "<div id='image'><img src='images_fichiers/image’" & ImgNbr & ".png' alt='description image'></div>"
ImgNbr = ImgNbr + 1
End Select
End If
Print #1, strtextToCopy
End If
End With
Next
Close #1
Call ExtractPitures(strMyProfilePath)
End Sub
Comme vous le constater nous appelons la méthode ExtractPictures à la fin de celle-ci. Nous allons la décrire dans la partie suivante.
Nous lui envoyons en paramètres la valeur incluse dans notre variable « strMyProfilePath » qui va nous permettre de transmettre le chemin vers le fichier Word correspondant.
III Extraction des images
L’extraction des images dans un document Word se fait naturellement en sauvegardant le fichier sous un format hmtl.
Nous allons voir comment effectuer cette opération à l’aide de VBA.
Pour commencer on déclare et initialise nos variables :
Dim imgDoc As InlineShape
Dim strFileExt As String
Dim nbrImage As Byte
Dim strSavePathName, strImgPathName As String
strFileExt = ".png"
strSavePathName = strProfilePath & "images"
ActiveDocument.SaveAs2 FileName:=strSavePathName & ".html", FileFormat:=wdFormatHTML
Comme vous pouvez le constater nous avons déclaré une variable imgDoc qui va permettre d’instancier un objet de type InlineShape.
Puis nous déclarons deux variables de type chaîne de caractères qui serviront à stocker l’extension des images que l’on va créer après avoir sauvegarder le document (strFileExt) et une autre permettant de stocker le répertoire de stockage des images (strSavePathName).
On applique ensuite la méthode SaveAs2 de l’objet ActiveDocument qui correspond à l’objet Document Word actuellement ouvert dans l’application. On lui donne en argument le chemin ainsi que l’extension voulue (.html). On précise aussi l’option wdFormatHTML.
Si vous regarder alors dans le dossier images les différents fichiers générés vous vous apercevrez que les images sont bien sauvegardées au bon emplacement mais les noms donnés à aux fichiers correspondants sont automatiques et générés de la façon suivante : image00+nbImage . On peut changer le nom de chaque image générée avec ce code :
For nbrImage = 0 To ActiveDocument.InlineShapes.Count - 1
srImgPathName = SavePathName & "_fichiers" & "\image00" & nbrImage + 1 & ".png"
Name PathName As strSavePathName & "_fichiers" & "\image" & nbrImage + 1 & ".png"
Next
La méthode Name permet de renommer chaque fichier image en substituant le nouveau format de nom de fichier au contenu de la variable strImgPathName. Nous allons donc nous retrouver avec des noms de fichiers comme image1.png, …, imageN.png
De plus cette sauvegarde automatique a pour inconvénient la génération de fichiers annexes non utiles pour notre processus.
En effet il y a en premier lieu le fichier html généré par Word avec son lot de balises qu’on ne souhaite pas intégrer dans un site Web et d’autres. Il va falloir donc les supprimer. Ceci est réalisé par les lignes de code suivantes :
Kill (strSavePathName & ".html")
Kill (strSavePathName & "_fichiers\" & "*.xml")
Kill (strSavePathName & "_fichiers\" & "*.thmx")
Sub ExtractPitures(ByVal strProfilePath As String)
Dim imgDoc As InlineShape
Dim strFileExt As String
Dim nbrImage As Byte
Dim strSavePathName, strPathName As String
strFileExt = ".png"
strSavePathName = ProfilePath & "images"
ActiveDocument.SaveAs2 FileName:=strSavePathName & ".html", FileFormat:=wdFormatHTML
For nbrImage = 0 To ActiveDocument.InlineShapes.Count - 1
strPathName = strSavePathName & "_fichiers" & "\image00" & nbrImage + 1 & ".png"
Name strPathName As strSavePathName & "_fichiers" & "\image" & nbrImage + 1 & ".png"
Next
ActiveDocument.Close
Kill (strSavePathName & ".html")
Kill (strSavePathName & "_fichiers\" & "*.xml")
Kill (strSavePathName & "_fichiers\" & "*.thmx")
End Sub
IV Conclusion
Ce tutoriel vous a permis de voir comment générer du code html propre à partir d’un document Word et ce en utilisant une simple macro VBA. A travers celui-ci vous avez pu apprendre quelques techniques pour parcourir les différents paragraphes et extraire le texte associé. Bien entendu je n’ai as traité tous les cas de figure comme la transcription des hyperliens en html via les balises d'ancre ou autre, mais vous avez les fondements pour aller plus loin et personnaliser votre script VBA pour qu’il réponde au mieux à vos besoins.

